Every model, one account. We curate, you choose.
Anthropic, OpenAI, Google, DeepSeek, Meta, Mistral, xAI — 38 models available through Vera Cloud. Pick any model you want for any task. One account, one bill, full transparency on every token.
Pick any model. Use it directly.
These aren't models we've wrapped or fine-tuned. They're the real thing — Claude, GPT, Gemini, DeepSeek, Llama, Mistral, Grok — available directly through one account. You choose which model to use for each task, each mode, each session.
No lock-in to a single provider. No guessing which model is behind an API. You see exactly what you're using and what it costs.
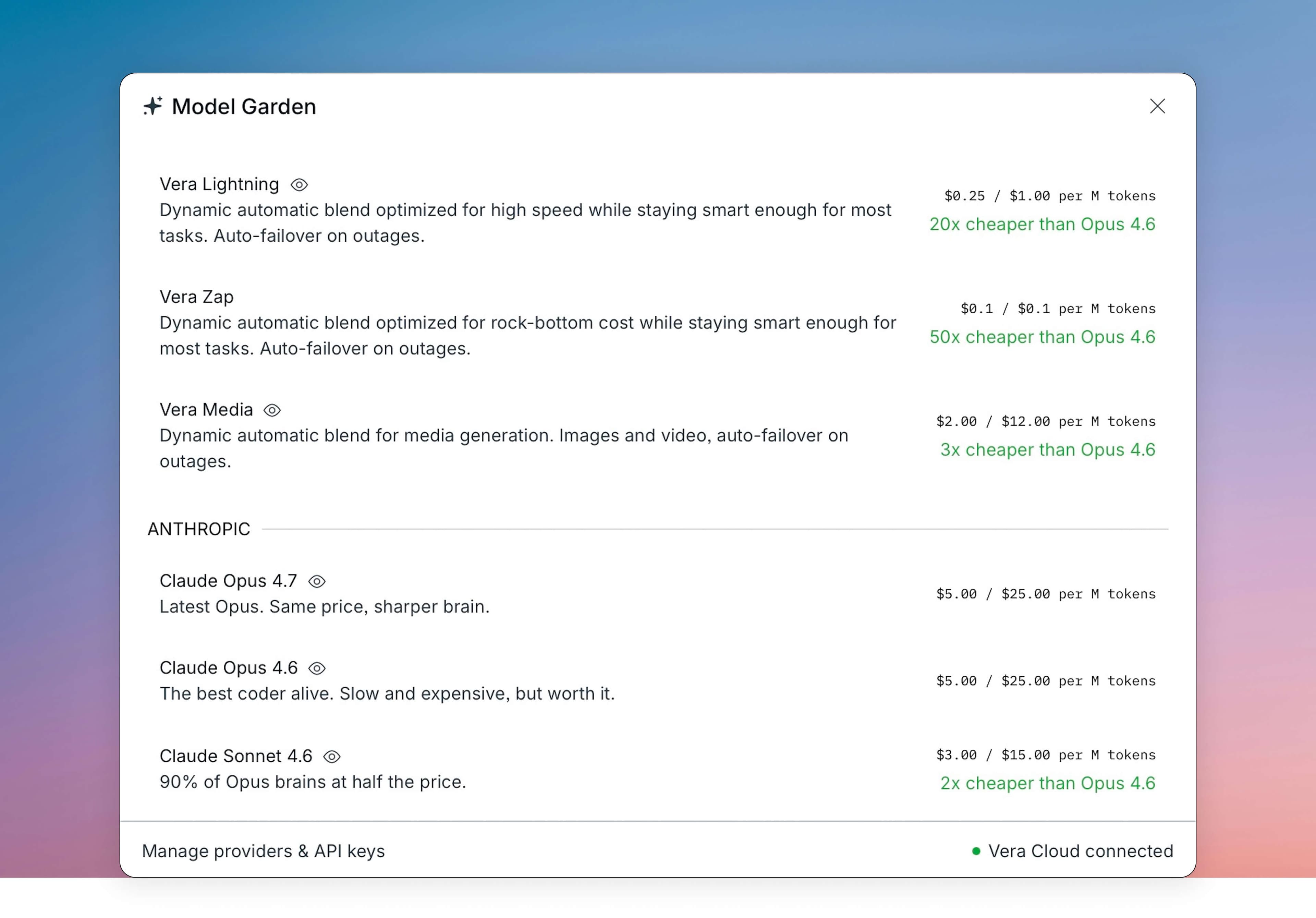
| Model | Provider | Speed | Notes |
|---|---|---|---|
| Claude Opus 4.7 | Anthropic | 36 tps | Latest Opus. Same price, sharper brain. |
| Claude Opus 4.6 | Anthropic | 36 tps | The best coder alive. Slow and expensive, but worth it. |
| Claude Sonnet 4.6 | Anthropic | 38 tps | 90% of Opus brains at half the price. |
| Claude Sonnet 4.5 | Anthropic | 52 tps | Previous-gen Sonnet. Still great, cheaper. |
| Claude Haiku 4.5 | Anthropic | 68 tps | Anthropic’s lightweight model. Fast and cheap. |
| Claude Haiku 3.5 | Anthropic | 27 tps | Legacy Haiku. Still available. |
| GPT-5.4 | OpenAI | 41 tps | OpenAI’s flagship. 2x cheaper than Opus. |
| GPT-5.4 Mini | OpenAI | 72 tps | Budget Codex. Handles most coding tasks just fine. |
| GPT-5.4 Nano | OpenAI | 88 tps | 20x cheaper than Opus. 88 tps. |
| GPT-5.3 Codex | OpenAI | 45 tps | Code-tuned 5.3. Strong on refactoring. |
| o3 | OpenAI | 12 tps | OpenAI’s reasoning model. Deep thinking, slow output. |
| o4-mini | OpenAI | 58 tps | Lightweight reasoning. Good for structured analysis. |
| Gemini 3 Pro | 73 tps | Google’s heavyweight. Million-token context window. | |
| Gemini 3 Flash | 88 tps | Fast and capable. Best bang-for-buck from Google. | |
| Gemini 3 Flash Lite | 90 tps | Google’s speed demon. 17x cheaper than Opus. | |
| Gemini 2.5 Pro | 64 tps | Previous-gen Pro. Still excellent for long context. | |
| DeepSeek V3.2 Speciale | DeepSeek | 27 tps | 21x cheaper than Opus. Strong on reasoning. |
| DeepSeek R1 | DeepSeek | 18 tps | Open-weight reasoning model. MIT licensed. |
| Llama 4 Scout | Meta | 82 tps | Open-weight. Fast and free to self-host. |
| Llama 4 Maverick | Meta | 65 tps | Meta’s large open model. Strong on code. |
| Mistral Large | Mistral AI | 44 tps | European flagship. Optimized for code generation. |
| Codestral | Mistral AI | 71 tps | Mistral’s dedicated coding model. |
| Grok 3 | xAI | 56 tps | xAI’s reasoning model. Real-time knowledge. |
| Grok 3 Mini | xAI | 78 tps | Lightweight Grok. Good speed-to-quality ratio. |
| MiniMax M2.7 | MiniMax | 37 tps | Punches way above its price. |
| Qwen 3 235B | Alibaba | 79 tps | 250x cheaper than Opus on Cerebras. |
| Qwen 3 32B | Alibaba | 120 tps | Tiny Qwen. Blazing on Groq. |
| GLM 4.7 | Zhipu AI | 61 tps | Chinese all-rounder. Strong multilingual support. |
| Kimi K2.5 | Moonshot | 48 tps | Long-context specialist. 128k native. |
| Llama 4 Scout (Cerebras) | Cerebras | 2,200 tps | Same model, 2,200 tps on Cerebras hardware. |
| Llama 4 Scout (Groq) | Groq | 1,400 tps | Same model, 1,400 tps on Groq LPUs. |
| Qwen 3 32B (Cerebras) | Cerebras | 1,800 tps | Same model, 1,800 tps on Cerebras. |
| Nano Banana Pro | — | Best image generation. Text-to-image built in. | |
| FAL Flux Pro | fal.ai | — | Fast image gen. Great for UI mockups and assets. |
| Kling v3 | fal.ai | — | Most consistent video gen we’ve tested. |
| Veo 3 | — | Google’s video model. Strong on cinematic style. | |
| ElevenLabs STT | ElevenLabs | — | Speech-to-text. Meeting transcription, voice notes. |
| ElevenLabs TTS | ElevenLabs | — | Text-to-speech. Natural voiceovers and audio. |
38models and counting. New models added as they ship — no update required on your end.
We've curated the best defaults so you don't have to.
We test every model and pick the best option for each job. Vera's three dynamic models route to whatever is strongest right now — they're our recommended defaults, and they update automatically as models improve.
Want a specific model instead? Swap any default for anything in the garden, any time.
Vera Frontier
Maximum intelligence. Always current.
Proxies to whatever is the best model right now — currently GPT-5.4 → Gemini 3.1 Pro → Opus 4.6. Auto-failover if a provider goes down.
Vera Deep
Thinking models for hard problems.
Routes to the best reasoning model available. Optimized for complex analysis and architectural decisions.
Vera Lightning
Fast and smart. Our default.
Routes across Cerebras and Groq for maximum speed with sub-second time-to-first-token.
Modes over models
Each mode has a default model — but you can swap it for any model in the garden. Want to plan with Opus and build with Flash? Go for it. Every combination works.
Defaults change as models improve. You always have full control.
| Mode | What it does | Default model |
|---|---|---|
| Interview | Conversational discovery | Vera Lightning |
| Plan | Thorough deliberation | Vera Deep |
| Build | Productive execution | Vera Lightning |
| Chat | Fast Q&A | Vera Lightning |
| Prototype | Visual mockups | Vera Lightning |
| QA Review | Rapid-fire triage | Vera Lightning |
| Document | Structured writing | Vera Lightning |
| Yeet | Full send | Vera Lightning |
Every default is swappable. Use any model from the garden for any mode, any time.
